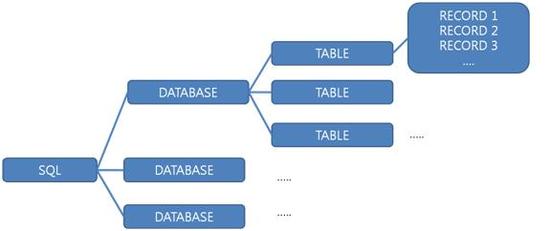
DATABASE –>여러 개의 TABLE -> 여러 개의 필드;
명령어들
-DATABASES-
*SHOW DATABASES; <현재 있는 데이터 베이스 이름을 본다.>
*USE 데이터베이스이름; <데이터베이스이름를 사용한다.>
*CREATE DATABASE 데이터베이스이름; <데이터베이스이름으로 데이터베이스를 만듬.>
*DROP DATABASE 데이터베이스이름; <데이터베이스이름의 데이터베이스를 삭제>
-DATABASE- :USE 데이터베이스이름; 명령으로 사용할 데이터베이스 선택해야함
*CREATE TABLE 테이블이름(구조) <데이터베이스안에 테이블를 만든다.>
Ex) CREATE TABLE aa(id INT AUTO_INCREMENT, name VARCHAR(30), old INT, exp INT, PRIMARY KEY(id));
-> 변수 선언할 때 (변수이름 변수형, ….. )
-> AUTO_INCREMENT 자동추가로 값을 입력할 때 NULL를 넣으면 자동 증가된다.
-> PRIMARY KEY(id) 명령은 테이블 내의 특정 변수를 검색하는데 있어서 데이터베이스를 최적화 하는데 사용된다. 뒤에 in는 가장 처음 선언한 변수로써 id를 가장 많이 검색하게 될 것이므로 id를 테이블의 primary key로 설정했다..
*SHOW TABLES; <데이터베이스안에 선언한 테이블 이름이 출력.>
*DESC 테이블이름; <데이터베이스안의 테이블이름의 구조를 본다.>
Ex) DESC aa; 라고 하면 aa라는 테이블 구조가 출력된다.
*INSERT INTO 테이블이름 VALUES (테이블 변수값);
Ex) INSERT INTO aa VALUES (NULL, ‘잭’, 14, 1431), (NULL, ‘룬’, 20, 14342) ;
->문자열 입력할때는 ‘룬’ 처럼 ‘ ‘ 안에 넣도록
*DROP TABLE aa;
데이터베이스 안의 aa 데이블 자체를 지운다.
<SELECT 테이블 데이타 검색>
*SELECT * FROM 테이블이름 <데이터베이스안의 테이블이름 모든 내용 값출력.>
*SELECT 찾는테이블변수이름 FROM 테이블이름
<데이터베이스안의 검색테이블변수이름에 대한 모든 값을 출력>
Ex) SELECT name,exp FROM aa; aa테이블 안의 name과 exp 부분값만 출력
*SELECT * FROM 테이블이름 WHERE 조건; 테이블안에 조건에 맞는 필드만 출력
Ex) SELECT *FROM aa WHERE exp > 1000; aa테이블 안의 exp부분값이 1000이상일것만 출력
확장 => SELECT id,name FROM aa WHERE old = 86; aa테이블 안의 old값이 86인것만 id과 name를 출력
=> SELECT * FROM aa WHERE old > 86 AND old<20; AND 명령어로 조건을 추가할 수 있다.
*SELECT * FROM aa WHERE name LIKE “J%”; <aa테이블의 name내용중 “J”로 시작하는 필드들 출력
=>LIKE는 부분 속하는것이다. 만약 LIKE “%S%” 로 검색하면 S문자가 포함된 모든 값들을 출력한다.
* SELECT * FROM aa WHERE name LIKE “J%” LIMIT 2; =제한.
<aa테이블의 name내용중 “J”로 시작하는 필드를 출력하는데 2개만 출력한다.>
<DELETE FROM 테이블에 필드 삭제. >
*DELETE FROM aa WHERE name = “Jeff”;
<aa테이블에서 이름이 Jeff인 필드를 삭제한다>
*DELETE FROM aa;
<aa테이블 안의 모든 필드를 지운다.>
<ALTER 테이블에 다른 필드 추가. >
*ALTER TABLE aa ADD lastTime TIMESTAMP;
<aa의 테이블안에 lastTime라는 이름에 TIMESTAMP 속성의 필드가 추가된다.>
즉 aa가 (id INT, name VARCHAR(30), old INT, exp INT); 였다면
위 명령실행후
Aa는 (id INT, name VARCHAR(30), old INT, exp INT, lastTime TIMESTAMP) 로 된다는 것이다.
*ALTER TABLE aa MODIFY name VARCHAR(50);
<aa의 테이블 안에 있는 name 변수를 VARCHAR(50)으로 속성을 바꾼다.>
<UPDATE 필드의 데이터 업데이트>
*UPDATA aa SET lasttime =NULL WHERE name = “Jeff”;
<aa의 테이블 안에 있는 name이 “Jeff”이 lasttime 속성의 값을 현재시간으로 업데이트한다.>
(TIMESTAMP는 NULL입력하면 현재시간으로 된다.)>
(만약 직접 입력하고 싶다면 NULL대신 20090722002000 처럼 입력하면된다. 앞에서부터 2009년 07월 22일 00시20분 00초 이다,)
확장 => 마지막에 LIKE 명령어로 해당 값이 들어간 모든 것에 수정할수 있다.
*UPDATA aa SET lasttime =NULL WHERE name LIKE “J%”;
->이름이 J시작하는 lasttime를 현재시간으로 업데이트한다.
<ORDER BY 출력 순서 정하기 > -기본이 오름차순이다.
*SELECT * FROM aa ORDER BY name; <aa테이블에서 name를 값중심으로 오름차순 정렬한다>
내림차순으로하려면 => *SELECT * FROM aa ORDER BY name DESC;
같은값이 나올 때 또다른 순서 => (ex) old 나이가 같은사람은 다음 경험치로 순서를 정하려면)
*SELECT * FROM aa ORDER BY old,exp;
<마지막 입력된데이터 구하기
1. SELECT @maxid:=MAX(id) FROM aa;
- @명령어로 maxid 이름을 변수를 선언하여 id필드로부터 가장 큰 값을 얻어 저장한다.
2. SELECT *FROM aa WHERE id = @maxid;
- 테이블 aa에서 id값이 maxid에 저장되 최대값인 필드만 출력한다.
*가장 늦은 시간값 구하는 방법
1. 마지막 시간을 가져온다.
SELECT @lastTime:=MAX(lastTime) FROM aa;
2.그 시간을 가지고 검색해서 가져온다.
SELECT * FROM aa WHERE lastTime =@lastTime;
이때 같은 이름을 했지만 지역 변수로 되어 중복되는 것이 아니다.
-기타.
*DB 백업하기 backup.sql 파일 만들기
콘솔화면에서 mysqldump 파일 있는 경로로 가서(보통 sql이 설치된 bin에 있다)
Mysqldump –u root –p DB데이타 이름 > 저장이름.sql
Ex) Mysqldump –u root –p gamedata > gamedata.sql
*gamedata.sql 파일 복원
컨솔화면에서 mysql –u root 넣을데이타베이스이름 < 넣을데이타.sql;
Ex) mysql –u root gamedata <gamedata.sql
중요한건 넣기전에 새로운DB가 없으면 안되니. CREATE DATABASE gamedata; 만들어줄것!
'DB > MySql' 카테고리의 다른 글
| mySQL Data Type (0) | 2014.02.21 |
|---|---|
| MySQL 함수 정리 (0) | 2014.02.21 |